A future of data science
Speaker: Allen Downey
Session description
In the hype cycle of data science, I suggest that the “peak of inflated expectations” was in 2012, the “trough of disillusionment” was in 2016, and since then, we have climbed the “slope of enlightenment”. Now, as we approach the “plateau of productivity”, it’s a good time to figure out how we got here and what future we want. Can we use data to answer questions, resolve debates, and make better decisions? What tools and processes make data science work? What can we learn when it does, and what goes wrong when it doesn’t? In this talk, I will present my answers, and then I would like to hear yours.
Session notes
If you encounter questions that is not answered, look into ressources/surveys with data that can answer the question.
Periods in data science “enthusiasm”
This talks in its whole revolves around when and why the events on the below image happens:

Theoretical vs. Computational Statistics
Theoretical Statistics:
- Traditionally (parametric) statistics focused on finding the “right” distribution or test.
Computational Statistics:
- Designed with the idea of “only one test” in mind, reducing the need to find the “right” test.
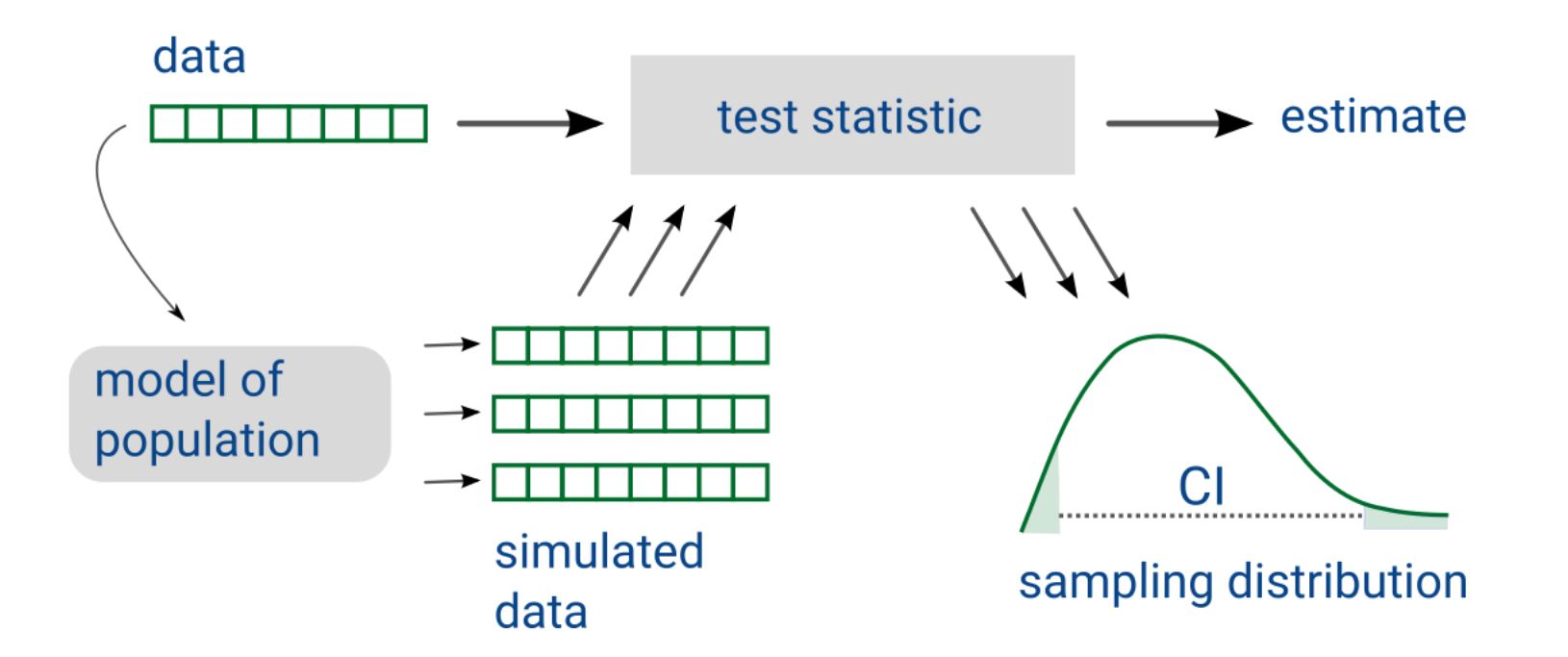
- Uses methods like bootstrap sampling to create synthetic samples and analyze data.
Example: Height Difference Between Men and Women
Bootstrap Sampling:
- Model data with bootstrap sampling to create synthetic samples.
- Calculate differences in means across these samples.
- Estimate 95% confidence intervals for the means.
Test on mean is just a t-test. But interested in variability. With stats we need to find the correct test for this, but with computational statistics, we just change our endpoint of the analyses.
Visualisation of “There is only one test” in computational statistics